何かしらの非同期なバッチ処理を実装したい場合にはSidekiqをActiveJobのバックエンドとして利用することが多いと思いますが、SidekiqはRedisに依存しており、個人のWebサービスとかでなるべくコストを抑えたいときにはRedisを立てずに実装したいものです。
今回はそういう場合に便利そうなPosgreSQLベースのGoodJobを使ってみたのでMEMO📝
github.com
GoodJobとは?
GoodJob is a multithreaded, Postgres-based, ActiveJob backend for Ruby on Rails.
good_job/README.md at main · bensheldon/good_job · GitHub
上記の記載の通り、マルチスレッドで動作するPostgresSQLベースのActiveJob backendです。
PostgresSQLベースのため、Redisを使わずにApplicationで使用しているデータベースでキューを管理することができます。
DBベースのActiveJob backendはDelayedJob等がありますが、GoodJobは以下の通り他と比較してMultithreadedで動作したり、structure.sqlが不要だったりする点が差別化要素となっているようです。
 good_job/README.md at main · bensheldon/good_job · GitHub
good_job/README.md at main · bensheldon/good_job · GitHub
1日に100万回エンキューぐらいの性能は担保されているようです👀
For most workloads. Targets full-stack teams, economy-minded solo developers, and applications that enqueue 1-million jobs/day and more.
good_job/README.md at main · bensheldon/good_job · GitHub
GoodJobの導入方法
GoodJobの導入は簡単で以下のREADMEに記載の通りですが、私がやった方法も記載しておきます。
https://github.com/bensheldon/good_job/blob/main/README.md#set-up
GoodJobのinstall
以下のコマンドを実行してGoodJobのinstall及び必要なtableのmigrationを実行します。
$ bundle add good_job
$ bin/rails g good_job:install
$ bin/rails db:migrate
GoodJobの初期設定
ActiveJobのバックエンドをGoodJobに変更します。
config.active_job.queue_adapter = :good_job
またconfig/initializers/good_job.rbのようなファイルを作成して、GoodJobの設定を行います。(私は以下のように設定してますが、環境に合わせて調整してください)
Rails.application.configure do
config.good_job.queues = '*'
config.good_job.execution_mode = :external
config.good_job.cleanup_preserved_jobs_before_seconds_ago = 1.hour.to_i
config.good_job.max_threads = 3
end
以下のコマンドを実行するとGoodJobを起動できます🙆
$ bundle exec good_job start
[GoodJob] [215] GoodJob started scheduler with queues=* max_threads=3.
Tips
Retry
GoodJobは以下の通りActiveJobのRetry機構を利用しています。
Retries
By default, GoodJob relies on ActiveJob's retry functionality.
ActiveJob can be configured to retry an infinite number of times, with an exponential backoff.
https://github.com/bensheldon/good_job/blob/main/README.md#retries
そのため以下のようにActiveJobのリトライ機構を利用してあげればRetryが行えます。
class FooJob < ApplicationJob
retry_on StandardError, attempts: 5
def perform(feed_id)
end
end
Sidekiqを使っていると以下のようなハマりポイントがあったりするので、逆に分かりやすいかもですね。
Active Jobのリトライは、単に「sidekiqに新しいジョブを実行させる」というもので、Active Job内で例外を出したジョブはsidekiq側では正常終了した扱いになります。Active Jobのジョブが5回連続で失敗して初めてsidekiq側で例外をキャッチします。
そしてsidekiqのリトライが始まります。sidekiqのリトライ回数はデフォルト25回です。
Railsクイズ、何問解けるかな? - SmartHR Tech Blog
Cron
GoodJobは以下の通りデフォルトでcronで定義できるスケジュール実行の機能を備えています。
GoodJob can enqueue jobs on a recurring basis that can be used as a replacement for cron.
https://github.com/bensheldon/good_job/blob/main/README.md#cron-style-repeatingrecurring-jobs
以下のような感じで設定に追記してあげると、毎時0分でFooJobを実行することができます。
Rails.application.configure do
config.good_job.enable_cron = true
config.good_job.cron = {
foo_job: { cron: '0 * * * *', class: 'FooJob' }
}
end
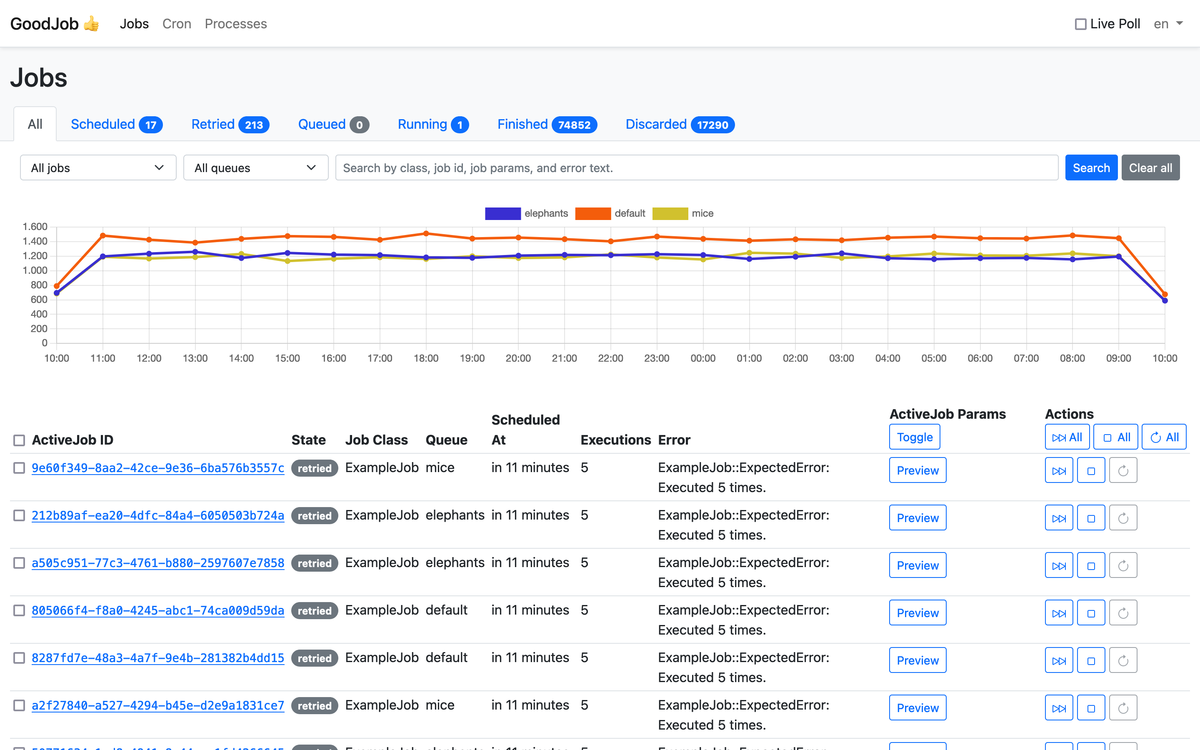
GoodJobはRails enginでDashboardを導入することができます。
GoodJob includes a Dashboard as a mountable Rails::Engine.
https://github.com/bensheldon/good_job/blob/main/README.md#dashboard
そのため以下のようにmountすればDashboardを導入することができます。
Rails.application.routes.draw do
namespace :admin do
authenticated :admin_user do
require 'good_job/engine'
mount GoodJob::Engine => 'good_job'
end
end
end
 https://github.com/bensheldon/good_job/blob/main/README.md#dashboard
https://github.com/bensheldon/good_job/blob/main/README.md#dashboard
おわりに
思ったよりも高機能で使いやすかったので開発初期でコストを抑えたいとか、インフラをシンプルにしたいとかそういう場合に良さそう✨